タイタニックの乗客の生存予測
タイタニックの乗客の生存予測は、Kaggle(予測モデリング及び分析手法関連プラットフォーム:いろんなデータを分析するひとがいるすごい場所)で有名なデータセットであるようです。
というわけで、タイタニックの乗客の生存予測をしてみましょう。
SIGNATE(いろんなデータを分析するひとがいるすごい場所、日本版)のチュートリアルでも扱われていて、もともとのデータがオープンソースであるようなので、権利関係なく自分でもやってみれそうでした。
実際にあった事故のデータということで、神妙な気持ちにはなりますが、題材としては非常に、興味深いものですね。
なお、私にはデータ分析の知識はまったくありませんので、ChatGPT頼りになります。
下準備:訓練用データと試験用データの分割
以下は日本語のタイタニックのデータセットの解説記事(@it)です。
というわけで、データは、ヴァンダービルト大学、生物統計学部の厚意により、こちらから取得しました。
データ数は、合計1309個。どうやら乗客オンリーのようです。なかなかの数ですが、機械学習するにしては心もとない数らしいです。また、データには欠損値があります。
あくまでも、練習用の課題、ということですね!
こんなデータだよ
データの中身は、こんな感じです。
- pclass:旅客クラス(1=1等、2=2等、3=3等)。裕福さの目安となる
- name:乗客の名前
- sex:性別(male=男性、female=女性)
- age:年齢。一部の乳児は小数値
- sibsp:タイタニック号に同乗している兄弟(Siblings)や配偶者(Spouses)の数
- parch:タイタニック号に同乗している親(Parents)や子供(Children)の数
- ticket:チケット番号
- fare:旅客運賃
- cabin:客室番号
- embarked:出港地(C=Cherbourg:シェルブール、Q=Queenstown:クイーンズタウン、S=Southampton:サウサンプトン)
- boat:救命ボート番号
- body:遺体収容時の識別番号
- home.dest:自宅または目的地
- survived:生存状況(0=死亡、1=生存)。通常はこの数値が目的変数として使われる
参考:Titanic:タイタニック号乗客者の生存状況(年齢や性別などの13項目)の表形式データセット
wikipediaによると、お金持ちのほうが生存率が高くって、男性よりも女性の方が生存率が高かったりするらしいですね。
実際に分析するとしたら、どこにどういう相関があるのか調べて、どの変数をどうまとめていくかが腕の見せ所なんでしょうかね。
データの下処理+分割(トレーニング用/テスト用)
とりあえず、訓練用データと試験用データを分割する必要があるらしいです。練習問題と本番テスト用。今日は同じ過去問は出しませんよっと……。どのくらいの割合がいいのかな、と思っていたのですが、SIGNATEでは半々くらいだったので半分でいいかなあ。SIGNATEだと、450個程度だったので、おそらく、採用を没にしたデータが400個くらいあるのでしょうね。
まあ、深いことは考えないで、ランダムにCSVを分割するスクリプトを書いていきましょう。
Python自体の環境構築については、以下を参照してください。

ここからスタート
今日は仮想環境を作るところもおさらいを兼ねて書いておきますね。
VSCodeを立ち上げたら、適当なフォルダを作って、ターミナルから、そこに仮想環境を作っていきます。
python -m venv venv
です。
仮想環境が出来たら、アクティベートします。
venv/Scripts/Activate
成功すると、こんな感じで頭に(venv)というのがくっつきます。

フォルダに、ダウンロードしてきた「titanic3.csv」を入れておきましょう。では、データの下処理をやっていきます。(だいたいChatGPT頼り)
❌ 除外が妥当なカラム
- name - 名前は通常、機械学習における説明変数として意味を持たない上に、ほぼユニーク(1307/1309ユニーク)。特徴量として不適。
- ticket - チケット番号もほぼユニークでランダム性が高く、規則性が取りにくい。
- cabin - 欠損が非常に多く(295/1309)、このままでは使いにくい。(※追記:取り入れる方向で調整するのもありえそうである。)
- boat - 救命ボートの番号。生存後に割り当てられた情報で、目的変数(survived)とリークの可能性がある。モデル精度を不正に高めてしまう。
- body - 遺体の番号。これも生死が分かったあとに付与された情報でリーク要素。
- home.dest - 自由記述型で表記揺れがあり、欠損も多い(745/1309)。標準化が面倒。
✅ 使える主なカラム
- pclass(客室の等級)
- sex(性別)
- age(年齢)※欠損はあるが、補完が可能
- sibsp(兄弟・配偶者の数)
- parch(親・子供の数)
- fare(料金)※1件だけ欠損
- embarked(乗船港)※2件だけ欠損
📌 欠損が少しあるので対応を考えるカラム
- age(263欠損)→ 平均/中央値補完、または「欠損かどうか」を特徴にする
- fare(1欠損)→ 平均/中央値補完でOK
- embarked(2欠損)→ 最頻値補完でOK
欠損値のあるデータも採用したのと、あと、結果の照合のために、「Passenger ID を追加」することにしました。
以下、スクリプトです。train.csvとanswer.csvを作成します。分割はランダムでいいんじゃないかと思ったんですが、sklearn(Pythonで機械学習を行うための超定番ライブラリ)には「いい感じに分割してくれる便利な機能」があるらしいですね。そうなんだ。
import pandas as pd
from sklearn.model_selection import train_test_split
# データ読み込み
df = pd.read_csv("titanic3.csv")
# 使用するカラム(目的変数含む)
selected_columns = ['pclass', 'sex', 'age', 'sibsp', 'parch', 'fare', 'embarked', 'survived']
df_selected = df[selected_columns].copy()
# Passenger ID を追加(0から始まる連番)
df_selected.insert(0, 'PassengerId', range(len(df_selected)))
# sex と embarked を数値に変換(欠損はそのまま)
df_selected['sex'] = df_selected['sex'].map({'male': 0, 'female': 1})
df_selected['embarked'] = df_selected['embarked'].map({'S': 0, 'C': 1, 'Q': 2})
# ランダムに50%ずつ分割
train_df, answer_df = train_test_split(df_selected, test_size=0.5, random_state=42)
# CSVに出力(indexは保存しない)
train_df.to_csv("train.csv", index=False)
answer_df.to_csv("answer.csv", index=False)
print("train.csv と answer.csv の分割が完了しました。")
じゃあ、このコードを divide_data.py みたいな名前で保存して、実行するわけです。python [半角スペース] [スクリプトのファイル名] で実行できます。私はいつも癖でpythonと打ってしまいますが、「py」でもいいです。
python divide_data.py
すると、エラーが出ます。
ModuleNotFoundError: No module named 'pandas'
こんな感じのエラーが出たら、ライブラリが足りていないということです。ターミナルから、pip install ナンタラ…… と入れていって、足りないライブラリをインストールします。今回はpandas(csvに使うやつ)とscikit-learn(データ処理に使うやつ)を入れます。一行ずつ入れてエンターでもいいしまとめてコピペしてエンターでもよい。
pip install pandas
pip install scikit-learn

実行すると、なんかハッカーっぽい感じのインストールがはじまり、すべてが上手くいくといいですよね(他力本願)。
今回は単純なので、大丈夫だと思いますが、たまーに引っかかります、numpyとかがね……。ついでにpip install updateしろと言われるのでやっておいた。
はじめてPythonを触ったときは「なんやねん」と思ったもんでした。本来、何かしら動かすときは「このライブラリが使いたいな。よし、インストールするか。できた。じゃあ、コードで使っていこう」という感じだと思いますが、ChatGPTに頼り始めてからは「とりあえず動かして、足りなかったら足す」という脳筋で解決しようとすることも多いです。肉じゃがでもつくってんのか?そうでなくても、ひとのコードを参考にしようとすると「requirements.txt」なんてインストールしてねリストがあったりするんですが、欠けてたり、最新ではなかったり、べつのライブラリと競合したりするので、手動で一個ずつやってくみたいな場面も多いです。numpyとか……numpyとか……。
もう一度実行してみると、こんどはライブラリが足りていたので、無事に分割されたようです。

答え合わせ用スクリプトを作っておこう
まず先に、予測結果のCSVから答えと照らし合わせて生存の正答率を出すスクリプトを書いてもらいましょう。check_result.py かなんかでいいでしょう。
import pandas as pd
# ファイル読み込み
answer_df = pd.read_csv("answer.csv")
predict_df = pd.read_csv("predict.csv")
# PassengerId でマージして照合
merged_df = pd.merge(answer_df[['PassengerId', 'survived']], predict_df[['PassengerId', 'survived']],
on='PassengerId', suffixes=('_true', '_pred'))
# 正答率計算
correct = (merged_df['survived_true'] == merged_df['survived_pred']).sum()
total = len(merged_df)
accuracy = correct / total
# 結果表示
print(f"照合件数: {total}")
print(f"正答数: {correct}")
print(f"正答率: {accuracy:.2%}")
これで準備が出来ました。
あほあほモンキーモデル
それでは、さっそく予測モデルを作ってみよう!の前に、なんかモデル作ってあれこれやっていまいちで凹むと悲しいので、ランダムでテキトーに予測するあほあほモンキーモデルを作っておきましょう。たんに1/2の確率で生き残ったかを出しています。これは、予測ではない。答え合わせ用スクリプトの動作確認も兼ねています。
random_predict.py を作成しておきます。
import pandas as pd
import numpy as np
# 正解データからPassengerIdを取得
answer_df = pd.read_csv("answer.csv")
passenger_ids = answer_df['PassengerId']
# 0 または 1 をランダムに予測
random_predictions = np.random.randint(0, 2, size=len(passenger_ids))
# 結果のDataFrameを作成
predict_df = pd.DataFrame({
'PassengerId': passenger_ids,
'survived': random_predictions
})
# CSVとして保存
predict_df.to_csv("predict.csv", index=False)
print("ランダム予測ファイル predict.csv を作成しました。")
random_predict.py を実行したあと、次に check_result.py を実行してください。
python random_predict.py
python check_result.py

正答率は、47%くらいらしいですね(予測を実行するたびに変化します)。
wikiによると、全体での死亡者の割合は68.1%くらいのようですが、このデータは乗客だけなのでもう少し生存率は高いはずです。クルーの方のほうが、たくさん亡くなられてるんですね。まあ47%くらいになってもおかしくはないか……。完璧にランダムなので、超絶運が良ければ100%に近い精度をたたき出すことがあるかもしれません。そんなことよりロトシックスでも買った方がマシである。私は好きだ、ボゴソートみたいなアホの概念が……。
ロジスティック回帰分析をしてみる
ロジスティック回帰分析は、「結果がYesかNoか(=0か1か)を確率で予測するための統計手法」らしいです。
……そうなんだ……。train_logistic.py に記述してもらいました。
import pandas as pd
from sklearn.linear_model import LogisticRegression
from sklearn.preprocessing import StandardScaler
from sklearn.impute import SimpleImputer
from sklearn.pipeline import Pipeline
# データ読み込み
train_df = pd.read_csv("train.csv")
answer_df = pd.read_csv("answer.csv")
# 特徴量と目的変数
X_train = train_df.drop(columns=["PassengerId", "survived"])
y_train = train_df["survived"]
X_test = answer_df.drop(columns=["PassengerId", "survived"])
passenger_ids = answer_df["PassengerId"]
# パイプライン:補完 → 標準化 → ロジスティック回帰
pipeline = Pipeline([
("imputer", SimpleImputer(strategy="mean")), # NaNを平均で補完
("scaler", StandardScaler()), # 標準化
("classifier", LogisticRegression()) # モデル
])
# 学習&予測
pipeline.fit(X_train, y_train)
y_pred = pipeline.predict(X_test)
# 出力
predict_df = pd.DataFrame({
"PassengerId": passenger_ids,
"survived": y_pred
})
predict_df.to_csv("predict.csv", index=False)
print("ロジスティック回帰モデルによる予測を完了しました(欠損補完あり)。")
欠損値でエラーが出たので、SimpleImputerで「平均値」を使用するようにしておきました。
python train_logistic.py
で実行してみます。
python check_result.py
結果を見てみると……。

およそ79.69%くらい当たるようになりました。
それじゃー、ちょっと改善、っていうのをしてみようかしらね。手っ取り早く分かるところで、欠損値の補完を、最頻値とか、中央値で補完したらいいかな、と思って改善しました。
数値は平均で補完+標準化、カテゴリは最頻値で補完としました。
改善後のコードは以下の通りです。
import pandas as pd
from sklearn.linear_model import LogisticRegression
from sklearn.preprocessing import StandardScaler
from sklearn.impute import SimpleImputer
from sklearn.compose import ColumnTransformer
from sklearn.pipeline import Pipeline
# データ読み込み
train_df = pd.read_csv("train.csv")
answer_df = pd.read_csv("answer.csv")
# 特徴量と目的変数
X_train = train_df.drop(columns=["PassengerId", "survived"])
y_train = train_df["survived"]
X_test = answer_df.drop(columns=["PassengerId", "survived"])
passenger_ids = answer_df["PassengerId"]
# 数値列とカテゴリ列を分ける
numeric_features = ["age", "sibsp", "parch", "fare"]
categorical_features = ["pclass", "sex", "embarked"]
# 前処理:数値は平均で補完+標準化、カテゴリは最頻値で補完(そのまま)
preprocessor = ColumnTransformer(
transformers=[
("num", Pipeline([
("imputer", SimpleImputer(strategy="mean")),
("scaler", StandardScaler())
]), numeric_features),
("cat", SimpleImputer(strategy="most_frequent"), categorical_features)
]
)
# パイプライン全体:前処理 → ロジスティック回帰
pipeline = Pipeline([
("preprocessor", preprocessor),
("classifier", LogisticRegression())
])
# 学習&予測
pipeline.fit(X_train, y_train)
y_pred = pipeline.predict(X_test)
# 結果出力
predict_df = pd.DataFrame({
"PassengerId": passenger_ids,
"survived": y_pred
})
predict_df.to_csv("predict.csv", index=False)
print("ロジスティック回帰モデルによる予測を完了しました(数値:平均、カテゴリ:最頻値で補完)。")
試してみたら、ちょっと結果が良くなって、8割ちょっきりになりました。

たまたまこうだったけど別のデータならどうなってたんだろう?divide_data.py を開いて……。
# ランダムに50%ずつ分割
train_df, answer_df = train_test_split(df_selected, test_size=0.5, random_state=72)
この train_test_split 関数の引数である random_state をテキトーな変数に変更して、何度かテストして、きゃっきゃしたりして遊びましょう。データの分割が変わるので、結果も変わります。
72にしてみると、82%くらいになりました。性能が上がったわけではなく、たまたま良い感じのデータだったのでしょうね。
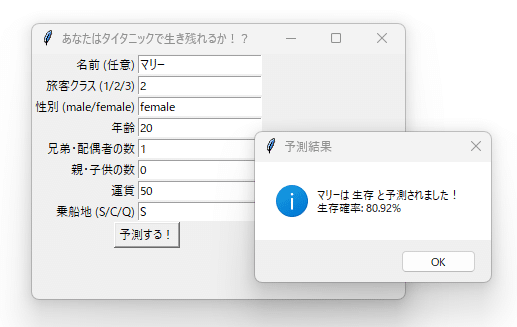
せっかくだったので、条件を指定して、生きるか死ぬかを予測するソフトも作ってみました。

2等級のジャック。新婚旅行(配偶者=1)。という設定。死んでしまった。

奥さん(という設定の)マリー。生存。女性だと生き残る確率が高い。

(以下、コードです。)
import pandas as pd
import numpy as np
from sklearn.linear_model import LogisticRegression
from sklearn.preprocessing import StandardScaler
from sklearn.impute import SimpleImputer
from sklearn.compose import ColumnTransformer
from sklearn.pipeline import Pipeline
import tkinter as tk
from tkinter import messagebox
# ---- 学習済みモデルの準備 ----
train_df = pd.read_csv("train.csv")
X_train = train_df.drop(columns=["PassengerId", "survived"])
y_train = train_df["survived"]
# 数値列とカテゴリ列
numeric_features = ["age", "sibsp", "parch", "fare"]
categorical_features = ["pclass", "sex", "embarked"]
# 前処理とモデル
preprocessor = ColumnTransformer([
("num", Pipeline([
("imputer", SimpleImputer(strategy="mean")),
("scaler", StandardScaler())
]), numeric_features),
("cat", SimpleImputer(strategy="most_frequent"), categorical_features)
])
pipeline = Pipeline([
("preprocessor", preprocessor),
("classifier", LogisticRegression())
])
pipeline.fit(X_train, y_train)
# ---- UIの準備 ----
def predict_survival():
try:
input_data = pd.DataFrame([{
"pclass": int(entry_pclass.get()),
"sex": 1 if entry_sex.get().lower() == "female" else 0,
"age": float(entry_age.get()),
"sibsp": int(entry_sibsp.get()),
"parch": int(entry_parch.get()),
"fare": float(entry_fare.get()),
"embarked": {"s": 0, "c": 1, "q": 2}.get(entry_embarked.get().lower(), 0)
}])
prediction = pipeline.predict(input_data)[0]
probability = pipeline.predict_proba(input_data)[0][1] * 100
name = entry_name.get()
message = f"{name or 'あなた'}は {"生存" if prediction else "死亡"} と予測されました!\n生存確率: {probability:.2f}%"
messagebox.showinfo("予測結果", message)
except Exception as e:
messagebox.showerror("エラー", f"入力エラー: {e}")
# GUIウィンドウ
root = tk.Tk()
root.title("あなたはタイタニックで生き残れるか!?")
fields = [
("名前 (任意)", "name"),
("旅客クラス (1/2/3)", "pclass"),
("性別 (male/female)", "sex"),
("年齢", "age"),
("兄弟・配偶者の数", "sibsp"),
("親・子供の数", "parch"),
("運賃", "fare"),
("乗船地 (S/C/Q)", "embarked")
]
entries = {}
for idx, (label_text, key) in enumerate(fields):
label = tk.Label(root, text=label_text)
label.grid(row=idx, column=0, sticky="e")
entry = tk.Entry(root)
entry.grid(row=idx, column=1)
entries[key] = entry
entry_name = entries["name"]
entry_pclass = entries["pclass"]
entry_sex = entries["sex"]
entry_age = entries["age"]
entry_sibsp = entries["sibsp"]
entry_parch = entries["parch"]
entry_fare = entries["fare"]
entry_embarked = entries["embarked"]
# 予測ボタン
button = tk.Button(root, text="予測する!", command=predict_survival)
button.grid(row=len(fields), column=0, columnspan=2)
root.mainloop()

まとめ
ロジスティック回帰分析ができました。できたようなんですが、できてますかこれ??? できたってことにしていいでしょうか? いかがでしたか?
SIGNATEのチュートリアルによると、次のステップでは、「学習用データのカテゴリ変数をダミー化するといい」らしいです。
こんなに分かっていない状態でも、ChatGPTに頼ると「とりあえず動く」、まで持って行けるのはすごいところです。
機械学習というおっかないトピックはいかつい数学が必要そうなので、おびえ、いつも毛を逆立てて威嚇していたんですが、SIGNATEのチュートリアルをやったら、与えられたデータがタブ区切りのシンプルなデータだわ、予測するデータが0か1かだわで「これならかじれる範囲のものかな?」と思えたのがとても大きかったです。
あと、トピックが、タイタニックの沈没という真剣になれて、興味があって、光景が浮かぶ良いタスクだったのも良かった。いかにもやりとげたようなことを書いているがコイツはSIGNATEのチュートリアルやっただけである。ほか、決定木分析とか、ランダムフォレストとか、やりたければ、いろいろ別のモデルでチャレンジできそうですね。
これで、何か面白いトピックとデータセットがあったら予測モデルが作れるようになりました。
割と、真面目にやろうと思ったら、結構なデータセットが必要だと思います。